What is DeepFakes
Deepfake is a technique for human image synthesis based on artificial intelligence. It is used to combine and superimpose existing images and videos onto source images or videos using a machine learning technique known as generative adversarial network.
DeepFakes(FaceSwap) Explained: Step by Step
Extract Faces
So here’s a problem. We have a ton of pictures and videos of both our subjects, but these are just of them doing stuff or in an environment with other people. Their bodies are on there, they’re on there with other people… It’s a mess. We can only train our bot if the data we have is consistent and focuses on the subject we want to swap. This is where FaceSwap first comes in.
A way to get around this is to collect a number of video clips which feature the people you want to face-swap. The extraction process refers to the process of extracting all frames from these video clips, identifying the faces and aligning them.
The alignment is critical, since the neural network that performs the face swap requires all faces to have the same size (usually 256×256 pixels) and features aligned. Detecting and aligning faces is a problem that is considered mostly solved, and is done by most applications very efficiently.

Face Detector: Detect Faces in Images
MTCNN Detector
class MTCNN():
""" MTCNN Detector for face alignment """
# TODO Batching for rnet and onet
def __init__(self, model_path, allow_growth, minsize, threshold, factor):
"""
minsize: minimum faces' size
threshold: threshold=[th1, th2, th3], th1-3 are three steps's threshold
factor: the factor used to create a scaling pyramid of face sizes to
detect in the image.
pnet, rnet, onet: caffemodel
"""
logger.debug("Initializing: %s: (model_path: '%s', allow_growth: %s, minsize: %s, "
"threshold: %s, factor: %s)", self.__class__.__name__, model_path,
allow_growth, minsize, threshold, factor)
self.minsize = minsize
self.threshold = threshold
self.factor = factor
self.pnet = PNet(model_path[0], allow_growth)
self.rnet = RNet(model_path[1], allow_growth)
self.onet = ONet(model_path[2], allow_growth)
self._pnet_scales = None
logger.debug("Initialized: %s", self.__class__.__name__)
def detect_faces(self, batch):
"""Detects faces in an image, and returns bounding boxes and points for them.
batch: input batch
"""
origin_h, origin_w = batch.shape[1:3]
rectangles = self.detect_pnet(batch, origin_h, origin_w)
rectangles = self.detect_rnet(batch, rectangles, origin_h, origin_w)
rectangles = self.detect_onet(batch, rectangles, origin_h, origin_w)
ret_boxes = list()
ret_points = list()
for rects in rectangles:
if rects:
total_boxes = np.array([result[:5] for result in rects])
points = np.array([result[5:] for result in rects]).T
else:
total_boxes = np.empty((0, 9))
points = np.empty(0)
ret_boxes.append(total_boxes)
ret_points.append(points)
return ret_boxes, ret_points
def detect_pnet(self, images, height, width):
# pylint: disable=too-many-locals
""" first stage - fast proposal network (pnet) to obtain face candidates """
if self._pnet_scales is None:
self._pnet_scales = calculate_scales(height, width, self.minsize, self.factor)
rectangles = [[] for _ in range(images.shape[0])]
batch_items = images.shape[0]
for scale in self._pnet_scales:
rwidth, rheight = int(width * scale), int(height * scale)
batch = np.empty((batch_items, rheight, rwidth, 3), dtype="float32")
for idx in range(batch_items):
batch[idx, ...] = cv2.resize(images[idx, ...], # pylint:disable=no-member
(rwidth, rheight))
output = self.pnet.predict(batch)
cls_prob = output[0][..., 1]
roi = output[1]
out_h, out_w = cls_prob.shape[1:3]
out_side = max(out_h, out_w)
cls_prob = np.swapaxes(cls_prob, 1, 2)
roi = np.swapaxes(roi, 1, 3)
for idx in range(batch_items):
# first index 0 = cls score, 1 = one hot repr
rectangle = detect_face_12net(cls_prob[idx, ...],
roi[idx, ...],
out_side,
1 / scale,
width,
height,
self.threshold[0])
rectangles[idx].extend(rectangle)
return [nms(x, 0.7, 'iou') for x in rectangles]
PNet Arch(RNet and ONet are similar)
class PNet(KSession):
""" Keras PNet model for MTCNN """
def __init__(self, model_path, allow_growth):
super().__init__("MTCNN-PNet", model_path, allow_growth=allow_growth)
self.define_model(self.model_definition)
self.load_model_weights()
@staticmethod
def model_definition():
""" Keras PNetwork for MTCNN """
input_ = Input(shape=(None, None, 3))
var_x = Conv2D(10, (3, 3), strides=1, padding='valid', name='conv1')(input_)
var_x = PReLU(shared_axes=[1, 2], name='PReLU1')(var_x)
var_x = MaxPool2D(pool_size=2)(var_x)
var_x = Conv2D(16, (3, 3), strides=1, padding='valid', name='conv2')(var_x)
var_x = PReLU(shared_axes=[1, 2], name='PReLU2')(var_x)
var_x = Conv2D(32, (3, 3), strides=1, padding='valid', name='conv3')(var_x)
var_x = PReLU(shared_axes=[1, 2], name='PReLU3')(var_x)
classifier = Conv2D(2, (1, 1), activation='softmax', name='conv4-1')(var_x)
bbox_regress = Conv2D(4, (1, 1), name='conv4-2')(var_x)
return [input_], [classifier, bbox_regress]
Face Aligner: Align Detected Faces
The FAN Alinger
How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks), Adrian Bulat and Georgios Tzimiropoulos, ICCV 2017
class Align(Aligner):
""" Perform transformation to align and get landmarks """
def __init__(self, **kwargs):
git_model_id = 9
model_filename = "face-alignment-network_2d4_keras_v1.h5"
super().__init__(git_model_id=git_model_id, model_filename=model_filename, **kwargs)
self.name = "FAN"
self.input_size = 256
self.colorformat = "RGB"
self.vram = 2240
self.vram_warnings = 512 # Will run at this with warnings
self.vram_per_batch = 64
self.batchsize = self.config["batch-size"]
self.reference_scale = 195
def init_model(self):
""" Initialize FAN model """
model_kwargs = dict(custom_objects={'TorchBatchNorm2D': TorchBatchNorm2D})
self.model = KSession(self.name,
self.model_path,
model_kwargs=model_kwargs,
allow_growth=self.config["allow_growth"])
self.model.load_model()
# Feed a placeholder so Aligner is primed for Manual tool
placeholder = np.zeros((self.batchsize, 3, self.input_size, self.input_size),
dtype="float32")
self.model.predict(placeholder)
def get_center_scale(self, detected_faces):
""" Get the center and set scale of bounding box """
logger.trace("Calculating center and scale")
l_center = []
l_scale = []
for face in detected_faces:
center = np.array([(face.left + face.right) / 2.0, (face.top + face.bottom) / 2.0])
center[1] -= face.h * 0.12
l_center.append(center)
l_scale.append((face.w + face.h) / self.reference_scale)
logger.trace("Calculated center and scale: %s, %s", l_center, l_scale)
return l_center, l_scale
def crop(self, batch): # pylint:disable=too-many-locals
""" Crop image around the center point """
logger.trace("Cropping images")
new_images = []
for face, center, scale in zip(batch["detected_faces"], *batch["center_scale"]):
is_color = face.image.ndim > 2
v_ul = self.transform([1, 1], center, scale, self.input_size).astype(np.int)
v_br = self.transform([self.input_size, self.input_size],
center,
scale,
self.input_size).astype(np.int)
if is_color:
new_dim = np.array([v_br[1] - v_ul[1],
v_br[0] - v_ul[0],
face.image.shape[2]],
dtype=np.int32)
new_img = np.zeros(new_dim, dtype=np.uint8)
else:
new_dim = np.array([v_br[1] - v_ul[1],
v_br[0] - v_ul[0]],
dtype=np.int)
new_img = np.zeros(new_dim, dtype=np.uint8)
height = face.image.shape[0]
width = face.image.shape[1]
new_x = np.array([max(1, -v_ul[0] + 1), min(v_br[0], width) - v_ul[0]],
dtype=np.int32)
new_y = np.array([max(1, -v_ul[1] + 1),
min(v_br[1], height) - v_ul[1]],
dtype=np.int32)
old_x = np.array([max(1, v_ul[0] + 1), min(v_br[0], width)],
dtype=np.int32)
old_y = np.array([max(1, v_ul[1] + 1), min(v_br[1], height)],
dtype=np.int32)
if is_color:
new_img[new_y[0] - 1:new_y[1],
new_x[0] - 1:new_x[1]] = face.image[old_y[0] - 1:old_y[1],
old_x[0] - 1:old_x[1], :]
else:
new_img[new_y[0] - 1:new_y[1],
new_x[0] - 1:new_x[1]] = face.image[old_y[0] - 1:old_y[1],
old_x[0] - 1:old_x[1]]
if new_img.shape[0] < self.input_size:
interpolation = cv2.INTER_CUBIC # pylint:disable=no-member
else:
interpolation = cv2.INTER_AREA # pylint:disable=no-member
new_images.append(cv2.resize(new_img, # pylint:disable=no-member
dsize=(int(self.input_size), int(self.input_size)),
interpolation=interpolation))
logger.trace("Cropped images")
return new_images
@staticmethod
def transform(point, center, scale, resolution):
""" Transform Image """
logger.trace("Transforming Points")
pnt = np.array([point[0], point[1], 1.0])
hscl = 200.0 * scale
eye = np.eye(3)
eye[0, 0] = resolution / hscl
eye[1, 1] = resolution / hscl
eye[0, 2] = resolution * (-center[0] / hscl + 0.5)
eye[1, 2] = resolution * (-center[1] / hscl + 0.5)
eye = np.linalg.inv(eye)
retval = np.matmul(eye, pnt)[0:2]
logger.trace("Transformed Points: %s", retval)
return retval
def predict(self, batch):
""" Predict the 68 point landmarks """
logger.trace("Predicting Landmarks")
batch["prediction"] = self.model.predict(batch["feed"])[-1]
logger.trace([pred.shape for pred in batch["prediction"]])
return batch
def get_pts_from_predict(self, batch):
""" Get points from predictor """
landmarks = []
for prediction, center, scale in zip(batch["prediction"], *batch["center_scale"]):
var_b = prediction.reshape((prediction.shape[0],
prediction.shape[1] * prediction.shape[2]))
var_c = var_b.argmax(1).reshape((prediction.shape[0],
1)).repeat(2,
axis=1).astype(np.float)
var_c[:, 0] %= prediction.shape[2]
var_c[:, 1] = np.apply_along_axis(
lambda x: np.floor(x / prediction.shape[2]),
0,
var_c[:, 1])
for i in range(prediction.shape[0]):
pt_x, pt_y = int(var_c[i, 0]), int(var_c[i, 1])
if 63 > pt_x > 0 and 63 > pt_y > 0:
diff = np.array([prediction[i, pt_y, pt_x+1]
- prediction[i, pt_y, pt_x-1],
prediction[i, pt_y+1, pt_x]
- prediction[i, pt_y-1, pt_x]])
var_c[i] += np.sign(diff)*0.25
var_c += 0.5
landmarks = [self.transform(var_c[i], center, scale, prediction.shape[2])
for i in range(prediction.shape[0])]
batch.setdefault("landmarks", []).append(landmarks)
Train Face-to-Face Translation Model
Ok, now you have a folder full of Trump faces and a folder full of Cage faces. What now? It’s time to train our bot! This creates a ‘model’ that contains information about what a Cage is and what a Trump is and how to swap between the two. In this case, it refers to the process which allows a neural network to convert a face into another.
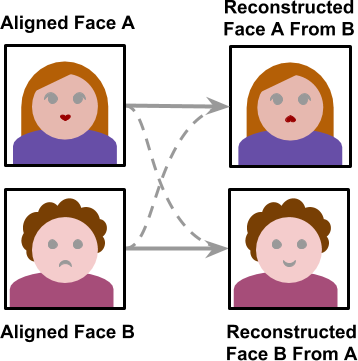
The Base Model Structure
class Model(ModelBase):
""" Original Faceswap Model """
def __init__(self, *args, **kwargs):
logger.debug("Initializing %s: (args: %s, kwargs: %s",
self.__class__.__name__, args, kwargs)
self.configfile = kwargs.get("configfile", None)
if "input_shape" not in kwargs:
kwargs["input_shape"] = (64, 64, 3)
if "encoder_dim" not in kwargs:
kwargs["encoder_dim"] = 512 if self.config["lowmem"] else 1024
super().__init__(*args, **kwargs)
logger.debug("Initialized %s", self.__class__.__name__)
def add_networks(self):
""" Add the original model weights """
logger.debug("Adding networks")
self.add_network("decoder", "a", self.decoder(), is_output=True)
self.add_network("decoder", "b", self.decoder(), is_output=True)
self.add_network("encoder", None, self.encoder())
logger.debug("Added networks")
def build_autoencoders(self, inputs):
""" Initialize original model """
logger.debug("Initializing model")
for side in ("a", "b"):
logger.debug("Adding Autoencoder. Side: %s", side)
decoder = self.networks["decoder_{}".format(side)].network
output = decoder(self.networks["encoder"].network(inputs[0]))
autoencoder = KerasModel(inputs, output)
self.add_predictor(side, autoencoder)
logger.debug("Initialized model")
def encoder(self):
""" Encoder Network """
input_ = Input(shape=self.input_shape)
var_x = input_
var_x = self.blocks.conv(var_x, 128)
var_x = self.blocks.conv(var_x, 256)
var_x = self.blocks.conv(var_x, 512)
if not self.config.get("lowmem", False):
var_x = self.blocks.conv(var_x, 1024)
var_x = Dense(self.encoder_dim)(Flatten()(var_x))
var_x = Dense(4 * 4 * 1024)(var_x)
var_x = Reshape((4, 4, 1024))(var_x)
var_x = self.blocks.upscale(var_x, 512)
return KerasModel(input_, var_x)
def decoder(self):
""" Decoder Network """
input_ = Input(shape=(8, 8, 512))
var_x = input_
var_x = self.blocks.upscale(var_x, 256)
var_x = self.blocks.upscale(var_x, 128)
var_x = self.blocks.upscale(var_x, 64)
var_x = self.blocks.conv2d(var_x, 3,
kernel_size=5,
padding="same",
activation="sigmoid",
name="face_out")
outputs = [var_x]
if self.config.get("mask_type", None):
var_y = input_
var_y = self.blocks.upscale(var_y, 256)
var_y = self.blocks.upscale(var_y, 128)
var_y = self.blocks.upscale(var_y, 64)
var_y = self.blocks.conv2d(var_y, 1,
kernel_size=5,
padding="same",
activation="sigmoid",
name="mask_out")
outputs.append(var_y)
return KerasModel(input_, outputs=outputs)
Loss Functions
Penalized Loss
def PenalizedLoss(mask, loss_func, # pylint: disable=invalid-name
mask_prop=1.0, mask_scaling=1.0, preprocessing_func=None):
""" Plaidml + tf Penalized loss function
mask_scaling: For multi-decoder output the target mask will likely be at
full size scaling, so this is the scaling factor to reduce
the mask by.
preprocessing_func: The preprocessing function to use. Should take a Keras Input
as it's only input
"""
def scale_mask(mask, scaling):
""" Scale the input mask to be the same size as the input face """
if scaling != 1.0:
size = round(1 / scaling)
mask = K.pool2d(mask,
pool_size=(size, size),
strides=(size, size),
padding="valid",
data_format=K.image_data_format(),
pool_mode="avg")
logger.debug("resized tensor: %s", mask)
return mask
mask = scale_mask(mask, mask_scaling)
if preprocessing_func is not None:
mask = preprocessing_func(mask)
mask_as_k_inv_prop = 1 - mask_prop
mask = (mask * mask_prop) + mask_as_k_inv_prop
def inner_loss(y_true, y_pred):
# Branching because tensorflows broadcasting is wonky and
# plaidmls concatenate is implemented ineficient.
if K.backend() == "plaidml.keras.backend":
n_true = y_true * mask
n_pred = y_pred * mask
else:
n_true = K.concatenate([y_true[:, :, :, i:i+1] * mask for i in range(3)], axis=-1)
n_pred = K.concatenate([y_pred[:, :, :, i:i+1] * mask for i in range(3)], axis=-1)
return loss_func(n_true, n_pred)
return inner_loss
Style Loss
def style_loss(gaussian_blur_radius=0.0, loss_weight=1.0, wnd_size=0, step_size=1):
""" Style Loss from DeepFaceLab
https://github.com/iperov/DeepFaceLab """
if gaussian_blur_radius > 0.0:
gblur = gaussian_blur(gaussian_blur_radius)
def std(content, style, loss_weight):
content_nc = K.int_shape(content)[-1]
style_nc = K.int_shape(style)[-1]
if content_nc != style_nc:
raise Exception("style_loss() content_nc != style_nc")
axes = [1, 2]
c_mean, c_var = K.mean(content, axis=axes, keepdims=True), K.var(content,
axis=axes,
keepdims=True)
s_mean, s_var = K.mean(style, axis=axes, keepdims=True), K.var(style,
axis=axes,
keepdims=True)
c_std, s_std = K.sqrt(c_var + 1e-5), K.sqrt(s_var + 1e-5)
mean_loss = K.sum(K.square(c_mean-s_mean))
std_loss = K.sum(K.square(c_std-s_std))
return (mean_loss + std_loss) * (loss_weight / float(content_nc))
def func(target, style):
if wnd_size == 0:
if gaussian_blur_radius > 0.0:
return std(gblur(target), gblur(style), loss_weight=loss_weight)
return std(target, style, loss_weight=loss_weight)
# currently unused
if K.backend() == "plaidml.keras.backend":
logger.warning("plaidML backend does not support style_loss. Disabling")
return 0
shp = K.int_shape(target)[1]
k = (shp - wnd_size) // step_size + 1
if gaussian_blur_radius > 0.0:
target, style = gblur(target), gblur(style)
target = tf.image.extract_image_patches(target,
[1, k, k, 1],
[1, 1, 1, 1],
[1, step_size, step_size, 1],
"VALID")
style = tf.image.extract_image_patches(style,
[1, k, k, 1],
[1, 1, 1, 1],
[1, step_size, step_size, 1],
"VALID")
return std(target, style, loss_weight)
return func
Cyclic Loss
def cyclic_loss(net_g1, net_g2, real1):
""" Cyclic Loss Function from Shoanlu GAN """
fake2 = net_g2(real1)[-1] # fake2 ABGR
fake2 = Lambda(lambda x: x[:, :, :, 1:])(fake2) # fake2 BGR
cyclic1 = net_g1(fake2)[-1] # cyclic1 ABGR
cyclic1 = Lambda(lambda x: x[:, :, :, 1:])(cyclic1) # cyclic1 BGR
loss = calc_loss(cyclic1, real1, loss='l1')
return loss
Convert Video
Once the training is complete, it is finally time to create a deepfake. Starting from a video, all frames are extracted and all faces are aligned. Then, each one is converted using the trained neural network. The final step is to merge the converted face back into the original frame. While this sounds like an easy task, it is actually where most face-swap applications go wrong.
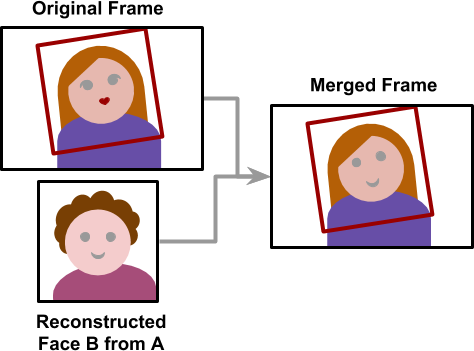
The creation process is the only one which does not use any Machine Learning. The algorithm to stitch a face back onto an image is hard-coded, and lacks the flexibility to detect mistakes.
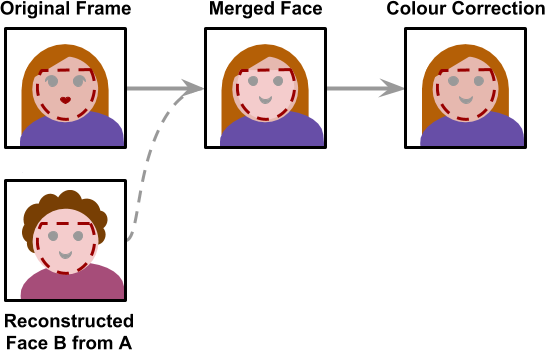
Also, each frame is processed independently; there is no temporal correlation between them, meaning that the final video might have some flickering. This is the part where more research is needed. If you are using faceswap instead of FakeApp, have a look at df which tries to improve the creation process.
Predict Faces from Input using trained model
class Predict():
""" Predict faces from incoming queue """
def __init__(self, in_queue, queue_size, arguments):
logger.debug("Initializing %s: (args: %s, queue_size: %s, in_queue: %s)",
self.__class__.__name__, arguments, queue_size, in_queue)
self.batchsize = self.get_batchsize(queue_size)
self.args = arguments
self.in_queue = in_queue
self.out_queue = queue_manager.get_queue("patch")
self.serializer = Serializer.get_serializer("json")
self.faces_count = 0
self.verify_output = False
self.model = self.load_model()
self.output_indices = {"face": self.model.largest_face_index,
"mask": self.model.largest_mask_index}
self.predictor = self.model.converter(self.args.swap_model)
self.queues = dict()
def predict_faces(self):
""" Get detected faces from images """
faces_seen = 0
consecutive_no_faces = 0
batch = list()
is_plaidml = GPUStats().is_plaidml
while True:
item = self.in_queue.get()
if item != "EOF":
faces_count = len(item["detected_faces"])
consecutive_no_faces = consecutive_no_faces + 1 if faces_count == 0 else 0
self.faces_count += faces_count
if faces_count > 1:
self.verify_output = True
self.load_aligned(item)
faces_seen += faces_count
batch.append(item)
if item != "EOF" and (faces_seen < self.batchsize and
consecutive_no_faces < self.batchsize):
faces_seen, consecutive_no_faces)
continue
if batch:
detected_batch = [detected_face for item in batch
for detected_face in item["detected_faces"]]
if faces_seen != 0:
feed_faces = self.compile_feed_faces(detected_batch)
batch_size = None
if is_plaidml and feed_faces.shape[0] != self.batchsize:
batch_size = 1
predicted = self.predict(feed_faces, batch_size)
else:
predicted = list()
self.queue_out_frames(batch, predicted)
consecutive_no_faces = 0
faces_seen = 0
batch = list()
if item == "EOF":
break
self.out_queue.put("EOF")
Overall Process Procedure
def patch_image(self, predicted):
""" Patch the image """
frame_size = (predicted["image"].shape[1], predicted["image"].shape[0])
new_image, background = self.get_new_image(predicted, frame_size)
patched_face = self.post_warp_adjustments(background, new_image)
patched_face = self.scale_image(patched_face)
patched_face *= 255.0
patched_face = np.rint(
patched_face,
out=np.empty(patched_face.shape, dtype="uint8"),
casting='unsafe'
)
if self.writer_pre_encode is not None:
patched_face = self.writer_pre_encode(patched_face)
return patched_face
Get New Images
for new_face, detected_face in zip(predicted["swapped_faces"],
predicted["detected_faces"]):
predicted_mask = new_face[:, :, -1] if new_face.shape[2] == 4 else None
new_face = new_face[:, :, :3]
src_face = detected_face.reference_face
interpolator = detected_face.reference_interpolators[1]
new_face = self.pre_warp_adjustments(src_face, new_face, detected_face, predicted_mask)
# Warp face with the mask
cv2.warpAffine(
new_face,
detected_face.reference_matrix,
frame_size,
placeholder,
flags=cv2.WARP_INVERSE_MAP | interpolator,
borderMode=cv2.BORDER_TRANSPARENT)
Conclusion
DeepFake FaceSwap utilize the State-of-the-Art techs from deep learning community, including face detection, face alignment, face reconstruction & translation, mask guided warping, etc.