Info
- Title: Few-Shot Unsupervised Image-to-Image Translation
- Task: Image-to-Image Translation
- Author: Ming-Yu Liu Xun Huang Arun Mallya Tero Karras Timo Aila Jaakko Lehtinen Jan Kautz
- Date: May 2019
- Arxiv: 1905.01723
- Published: ICCV 2019
Abstract
Unsupervised image-to-image translation methods learn to map images in a given class to an analogous image in a different class, drawing on unstructured (non-registered) datasets of images. While remarkably successful, current methods require access to many images in both source and destination classes at training time. We argue this greatly limits their use. Drawing inspiration from the human capability of picking up the essence of a novel object from a small number of examples and generalizing from there, we seek a few-shot, unsupervised image-to-image translation algorithm that works on previously unseen target classes that are specified, at test time, only by a few example images. Our model achieves this few-shot generation capability by coupling an adversarial training scheme with a novel network design. Through extensive experimental validation and comparisons to several baseline methods on benchmark datasets, we verify the effectiveness of the proposed framework.
Motivation & Design
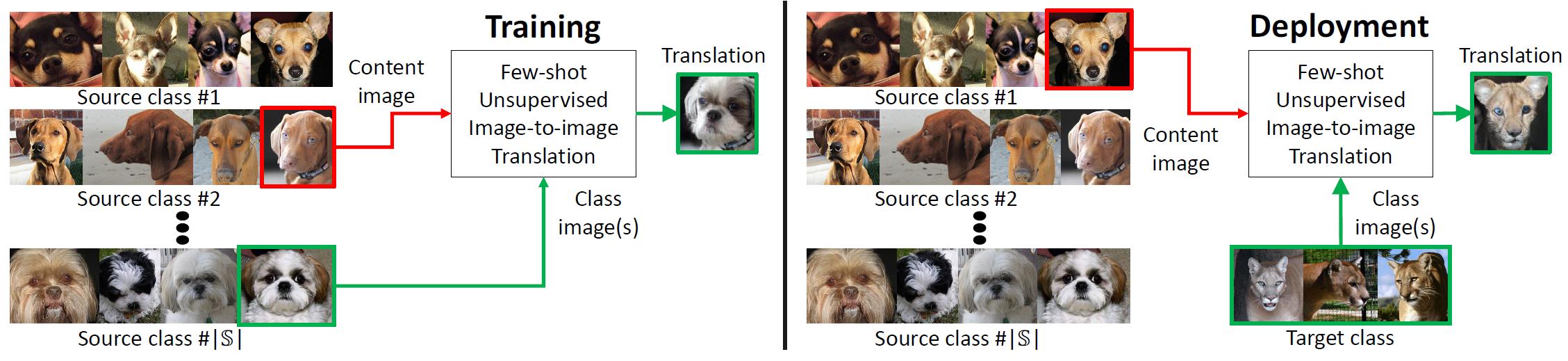
While unsupervised/unpaired image-to-image translation methods (e.g., Liu and Tuzel, Liu et. al., Zhu et. al., and Huang et. al.) have achieved remarkable success, they are still limited in two aspects.
First, they generally require seeing a lot of images from target class in the training time.
Second, a trained model for a translation task cannot be repurposed for another translation task in the test time.
We propose a few-shot unsupervised image-to-image translation framework (FUNIT) to address the limitation. In the training time, the FUNIT model learns to translate images between any two classes sampled from a set of source classes. In the test time, the model is presented a few images of a target class that the model has never seen before. The model leverages these few example images to translate an input image of a source class to the target class.
The Generator
To generate a translation output $x̄$, the translator combines the class latent code z y extracted from the class images $y_1$,…, $y_k$ with the content latent code z x extracted from the input content image. Note that nonlinearity and normalization operations are not included in the visualization.

The Multi-task Discriminator
Our discriminator D is trained by solving multiple adversarial classification tasks simultaneously. Each of the tasks is a binary classification task determining whether an input image is a real image of the source class or a translation output coming from G. As there are $S$ source classes, D produces $S$ outputs. When updating D for a real image of source class $c_X$, we penalize D if its $c_X$th output is false. For a translation output yielding a fake image of source class $c_X$, we penalize D if its $c_X$th output is positive. We do not penalize D for not predicting false for images of other classes (S{$c_X$}). When updating G, we only penalize G if the $c_X$ th output of D is false.
Code
class FUNITModel(nn.Module):
def __init__(self, hp):
super(FUNITModel, self).__init__()
self.gen = FewShotGen(hp['gen'])
self.dis = GPPatchMcResDis(hp['dis'])
self.gen_test = copy.deepcopy(self.gen)
def forward(self, co_data, cl_data, hp, mode):
xa = co_data[0].cuda()
la = co_data[1].cuda()
xb = cl_data[0].cuda()
lb = cl_data[1].cuda()
if mode == 'gen_update':
c_xa = self.gen.enc_content(xa)
s_xa = self.gen.enc_class_model(xa)
s_xb = self.gen.enc_class_model(xb)
xt = self.gen.decode(c_xa, s_xb) # translation
xr = self.gen.decode(c_xa, s_xa) # reconstruction
l_adv_t, gacc_t, xt_gan_feat = self.dis.calc_gen_loss(xt, lb)
l_adv_r, gacc_r, xr_gan_feat = self.dis.calc_gen_loss(xr, la)
_, xb_gan_feat = self.dis(xb, lb)
_, xa_gan_feat = self.dis(xa, la)
l_c_rec = recon_criterion(xr_gan_feat.mean(3).mean(2),
xa_gan_feat.mean(3).mean(2))
l_m_rec = recon_criterion(xt_gan_feat.mean(3).mean(2),
xb_gan_feat.mean(3).mean(2))
l_x_rec = recon_criterion(xr, xa)
l_adv = 0.5 * (l_adv_t + l_adv_r)
acc = 0.5 * (gacc_t + gacc_r)
l_total = (hp['gan_w'] * l_adv + hp['r_w'] * l_x_rec + hp[
'fm_w'] * (l_c_rec + l_m_rec))
l_total.backward()
return l_total, l_adv, l_x_rec, l_c_rec, l_m_rec, acc
elif mode == 'dis_update':
xb.requires_grad_()
l_real_pre, acc_r, resp_r = self.dis.calc_dis_real_loss(xb, lb)
l_real = hp['gan_w'] * l_real_pre
l_real.backward(retain_graph=True)
l_reg_pre = self.dis.calc_grad2(resp_r, xb)
l_reg = 10 * l_reg_pre
l_reg.backward()
with torch.no_grad():
c_xa = self.gen.enc_content(xa)
s_xb = self.gen.enc_class_model(xb)
xt = self.gen.decode(c_xa, s_xb)
l_fake_p, acc_f, resp_f = self.dis.calc_dis_fake_loss(xt.detach(),
lb)
l_fake = hp['gan_w'] * l_fake_p
l_fake.backward()
l_total = l_fake + l_real + l_reg
acc = 0.5 * (acc_f + acc_r)
return l_total, l_fake_p, l_real_pre, l_reg_pre, acc
else:
assert 0, 'Not support operation'
def translate_k_shot(self, co_data, cl_data, k):
self.eval()
xa = co_data[0].cuda()
xb = cl_data[0].cuda()
c_xa_current = self.gen_test.enc_content(xa)
if k == 1:
c_xa_current = self.gen_test.enc_content(xa)
s_xb_current = self.gen_test.enc_class_model(xb)
xt_current = self.gen_test.decode(c_xa_current, s_xb_current)
else:
s_xb_current_before = self.gen_test.enc_class_model(xb)
s_xb_current_after = s_xb_current_before.squeeze(-1).permute(1,
2,
0)
s_xb_current_pool = torch.nn.functional.avg_pool1d(
s_xb_current_after, k)
s_xb_current = s_xb_current_pool.permute(2, 0, 1).unsqueeze(-1)
xt_current = self.gen_test.decode(c_xa_current, s_xb_current)
return xt_current
def compute_k_style(self, style_batch, k):
self.eval()
style_batch = style_batch.cuda()
s_xb_before = self.gen_test.enc_class_model(style_batch)
s_xb_after = s_xb_before.squeeze(-1).permute(1, 2, 0)
s_xb_pool = torch.nn.functional.avg_pool1d(s_xb_after, k)
s_xb = s_xb_pool.permute(2, 0, 1).unsqueeze(-1)
return s_xb
def translate_simple(self, content_image, class_code):
self.eval()
xa = content_image.cuda()
s_xb_current = class_code.cuda()
c_xa_current = self.gen_test.enc_content(xa)
xt_current = self.gen_test.decode(c_xa_current, s_xb_current)
return xt_current
def test(self, co_data, cl_data):
self.eval()
self.gen.eval()
self.gen_test.eval()
xa = co_data[0].cuda()
xb = cl_data[0].cuda()
c_xa_current = self.gen.enc_content(xa)
s_xa_current = self.gen.enc_class_model(xa)
s_xb_current = self.gen.enc_class_model(xb)
xt_current = self.gen.decode(c_xa_current, s_xb_current)
xr_current = self.gen.decode(c_xa_current, s_xa_current)
c_xa = self.gen_test.enc_content(xa)
s_xa = self.gen_test.enc_class_model(xa)
s_xb = self.gen_test.enc_class_model(xb)
xt = self.gen_test.decode(c_xa, s_xb)
xr = self.gen_test.decode(c_xa, s_xa)
self.train()
return xa, xr_current, xt_current, xb, xr, xt
Generator
class FewShotGen(nn.Module):
def __init__(self, hp):
super(FewShotGen, self).__init__()
nf = hp['nf']
nf_mlp = hp['nf_mlp']
down_class = hp['n_downs_class']
down_content = hp['n_downs_content']
n_mlp_blks = hp['n_mlp_blks']
n_res_blks = hp['n_res_blks']
latent_dim = hp['latent_dim']
self.enc_class_model = ClassModelEncoder(down_class,
3,
nf,
latent_dim,
norm='none',
activ='relu',
pad_type='reflect')
self.enc_content = ContentEncoder(down_content,
n_res_blks,
3,
nf,
'in',
activ='relu',
pad_type='reflect')
self.dec = Decoder(down_content,
n_res_blks,
self.enc_content.output_dim,
3,
res_norm='adain',
activ='relu',
pad_type='reflect')
self.mlp = MLP(latent_dim,
get_num_adain_params(self.dec),
nf_mlp,
n_mlp_blks,
norm='none',
activ='relu')
def forward(self, one_image, model_set):
# reconstruct an image
content, model_codes = self.encode(one_image, model_set)
model_code = torch.mean(model_codes, dim=0).unsqueeze(0)
images_trans = self.decode(content, model_code)
return images_trans
def encode(self, one_image, model_set):
# extract content code from the input image
content = self.enc_content(one_image)
# extract model code from the images in the model set
class_codes = self.enc_class_model(model_set)
class_code = torch.mean(class_codes, dim=0).unsqueeze(0)
return content, class_code
def decode(self, content, model_code):
# decode content and style codes to an image
adain_params = self.mlp(model_code)
assign_adain_params(adain_params, self.dec)
images = self.dec(content)
return images
ClassModelEncoder
class ClassModelEncoder(nn.Module):
def __init__(self, downs, ind_im, dim, latent_dim, norm, activ, pad_type):
super(ClassModelEncoder, self).__init__()
self.model = []
self.model += [Conv2dBlock(ind_im, dim, 7, 1, 3,
norm=norm,
activation=activ,
pad_type=pad_type)]
for i in range(2):
self.model += [Conv2dBlock(dim, 2 * dim, 4, 2, 1,
norm=norm,
activation=activ,
pad_type=pad_type)]
dim *= 2
for i in range(downs - 2):
self.model += [Conv2dBlock(dim, dim, 4, 2, 1,
norm=norm,
activation=activ,
pad_type=pad_type)]
self.model += [nn.AdaptiveAvgPool2d(1)]
self.model += [nn.Conv2d(dim, latent_dim, 1, 1, 0)]
self.model = nn.Sequential(*self.model)
self.output_dim = dim
def forward(self, x):
return self.model(x)
ContentEncoder
class ContentEncoder(nn.Module):
def __init__(self, downs, n_res, input_dim, dim, norm, activ, pad_type):
super(ContentEncoder, self).__init__()
self.model = []
self.model += [Conv2dBlock(input_dim, dim, 7, 1, 3,
norm=norm,
activation=activ,
pad_type=pad_type)]
for i in range(downs):
self.model += [Conv2dBlock(dim, 2 * dim, 4, 2, 1,
norm=norm,
activation=activ,
pad_type=pad_type)]
dim *= 2
self.model += [ResBlocks(n_res, dim,
norm=norm,
activation=activ,
pad_type=pad_type)]
self.model = nn.Sequential(*self.model)
self.output_dim = dim
def forward(self, x):
return self.model(x)
Decoder
class Decoder(nn.Module):
def __init__(self, ups, n_res, dim, out_dim, res_norm, activ, pad_type):
super(Decoder, self).__init__()
self.model = []
self.model += [ResBlocks(n_res, dim, res_norm,
activ, pad_type=pad_type)]
for i in range(ups):
self.model += [nn.Upsample(scale_factor=2),
Conv2dBlock(dim, dim // 2, 5, 1, 2,
norm='in',
activation=activ,
pad_type=pad_type)]
dim //= 2
self.model += [Conv2dBlock(dim, out_dim, 7, 1, 3,
norm='none',
activation='tanh',
pad_type=pad_type)]
self.model = nn.Sequential(*self.model)
def forward(self, x):
return self.model(x)
Discriminator
class GPPatchMcResDis(nn.Module):
def __init__(self, hp):
super(GPPatchMcResDis, self).__init__()
assert hp['n_res_blks'] % 2 == 0, 'n_res_blk must be multiples of 2'
self.n_layers = hp['n_res_blks'] // 2
nf = hp['nf']
cnn_f = [Conv2dBlock(3, nf, 7, 1, 3,
pad_type='reflect',
norm='none',
activation='none')]
for i in range(self.n_layers - 1):
nf_out = np.min([nf * 2, 1024])
cnn_f += [ActFirstResBlock(nf, nf, None, 'lrelu', 'none')]
cnn_f += [ActFirstResBlock(nf, nf_out, None, 'lrelu', 'none')]
cnn_f += [nn.ReflectionPad2d(1)]
cnn_f += [nn.AvgPool2d(kernel_size=3, stride=2)]
nf = np.min([nf * 2, 1024])
nf_out = np.min([nf * 2, 1024])
cnn_f += [ActFirstResBlock(nf, nf, None, 'lrelu', 'none')]
cnn_f += [ActFirstResBlock(nf, nf_out, None, 'lrelu', 'none')]
cnn_c = [Conv2dBlock(nf_out, hp['num_classes'], 1, 1,
norm='none',
activation='lrelu',
activation_first=True)]
self.cnn_f = nn.Sequential(*cnn_f)
self.cnn_c = nn.Sequential(*cnn_c)
def forward(self, x, y):
assert(x.size(0) == y.size(0))
feat = self.cnn_f(x)
out = self.cnn_c(feat)
index = torch.LongTensor(range(out.size(0))).cuda()
out = out[index, y, :, :]
return out, feat
def calc_dis_fake_loss(self, input_fake, input_label):
resp_fake, gan_feat = self.forward(input_fake, input_label)
total_count = torch.tensor(np.prod(resp_fake.size()),
dtype=torch.float).cuda()
fake_loss = torch.nn.ReLU()(1.0 + resp_fake).mean()
correct_count = (resp_fake < 0).sum()
fake_accuracy = correct_count.type_as(fake_loss) / total_count
return fake_loss, fake_accuracy, resp_fake
def calc_dis_real_loss(self, input_real, input_label):
resp_real, gan_feat = self.forward(input_real, input_label)
total_count = torch.tensor(np.prod(resp_real.size()),
dtype=torch.float).cuda()
real_loss = torch.nn.ReLU()(1.0 - resp_real).mean()
correct_count = (resp_real >= 0).sum()
real_accuracy = correct_count.type_as(real_loss) / total_count
return real_loss, real_accuracy, resp_real
def calc_gen_loss(self, input_fake, input_fake_label):
resp_fake, gan_feat = self.forward(input_fake, input_fake_label)
total_count = torch.tensor(np.prod(resp_fake.size()),
dtype=torch.float).cuda()
loss = -resp_fake.mean()
correct_count = (resp_fake >= 0).sum()
accuracy = correct_count.type_as(loss) / total_count
return loss, accuracy, gan_feat
def calc_grad2(self, d_out, x_in):
batch_size = x_in.size(0)
grad_dout = autograd.grad(outputs=d_out.mean(),
inputs=x_in,
create_graph=True,
retain_graph=True,
only_inputs=True)[0]
grad_dout2 = grad_dout.pow(2)
assert (grad_dout2.size() == x_in.size())
reg = grad_dout2.sum()/batch_size
return reg
Training
class Trainer(nn.Module):
def __init__(self, cfg):
super(Trainer, self).__init__()
self.model = FUNITModel(cfg)
lr_gen = cfg['lr_gen']
lr_dis = cfg['lr_dis']
dis_params = list(self.model.dis.parameters())
gen_params = list(self.model.gen.parameters())
self.dis_opt = torch.optim.RMSprop(
[p for p in dis_params if p.requires_grad],
lr=lr_gen, weight_decay=cfg['weight_decay'])
self.gen_opt = torch.optim.RMSprop(
[p for p in gen_params if p.requires_grad],
lr=lr_dis, weight_decay=cfg['weight_decay'])
self.dis_scheduler = get_scheduler(self.dis_opt, cfg)
self.gen_scheduler = get_scheduler(self.gen_opt, cfg)
self.apply(weights_init(cfg['init']))
self.model.gen_test = copy.deepcopy(self.model.gen)
def gen_update(self, co_data, cl_data, hp, multigpus):
self.gen_opt.zero_grad()
al, ad, xr, cr, sr, ac = self.model(co_data, cl_data, hp, 'gen_update')
self.loss_gen_total = torch.mean(al)
self.loss_gen_recon_x = torch.mean(xr)
self.loss_gen_recon_c = torch.mean(cr)
self.loss_gen_recon_s = torch.mean(sr)
self.loss_gen_adv = torch.mean(ad)
self.accuracy_gen_adv = torch.mean(ac)
self.gen_opt.step()
this_model = self.model.module if multigpus else self.model
update_average(this_model.gen_test, this_model.gen)
return self.accuracy_gen_adv.item()
def dis_update(self, co_data, cl_data, hp):
self.dis_opt.zero_grad()
al, lfa, lre, reg, acc = self.model(co_data, cl_data, hp, 'dis_update')
self.loss_dis_total = torch.mean(al)
self.loss_dis_fake_adv = torch.mean(lfa)
self.loss_dis_real_adv = torch.mean(lre)
self.loss_dis_reg = torch.mean(reg)
self.accuracy_dis_adv = torch.mean(acc)
self.dis_opt.step()
return self.accuracy_dis_adv.item()
Related
- Image to Image Translation(1): pix2pix, S+U, CycleGAN, UNIT, BicycleGAN, and StarGAN
-
Image to Image Translation(2): pix2pixHD, MUNIT, DRIT, vid2vid, SPADE and INIT
- (DMIT)Multi-mapping Image-to-Image Translation via Learning Disentanglement - Xiaoming Yu - NIPS 2019
- U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation - Junho Kim - 2019
- Towards Instance-level Image-to-Image Translation - Shen - CVPR 2019